# Learning Collaborative Action Plans from YouTube Videos
Objective
希望可以從煮菜影片中學習到兩人做了哪些動作,其中又包含哪些合作的 action,進而讓機器人未來有能力跟人類一起完成一件任務。
Related Work
有一篇最相關的工作,主要是用 grammar tree 描述一個人在進行的動作,但因為機器人在現實生活中也很有可能要跟其他人互動,所以我們希望可以讓機器人學習兩個人的 action sequence,進而在未來有可能跟人一起合作。
Method
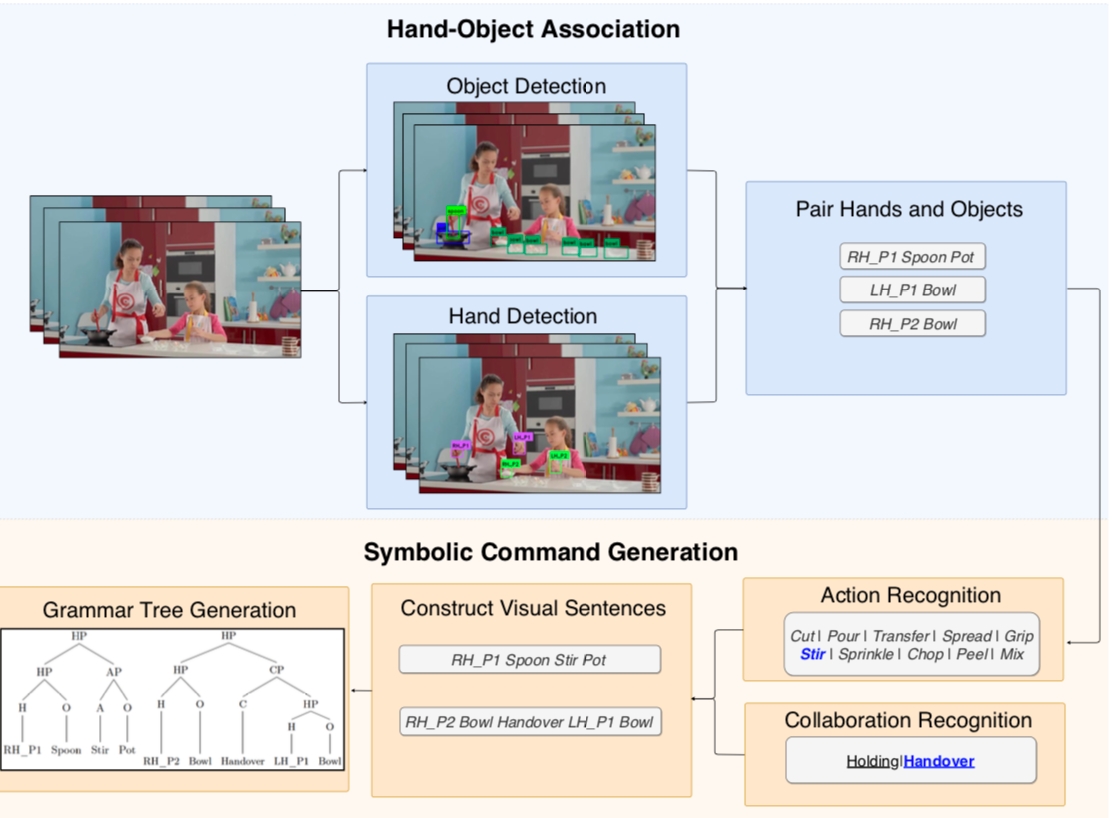
我們主要的流程如下圖:
底層: 1. Object Detection:用 YOLO v3 (pretrained by COCO dataset) 來做物體辨識。 2. Hand detection:用 SSD + OpenPose 來做 hand detection。
中層: 3. 將 hand 跟 person 接起來:OpenPose 4. 跟 hand 跟 object pair 起來:
分成兩個 round
Round 1: 把每個手跟最近的 obj pair 起來(距離必須小於 threshold)
Round 2: 檢查每個被手抓住的 obj 有沒有 manipulate 其他 obj,有的話就產生 hand-obj-obj tuple(中間的 obj 需要是 tool)
Robustness: 會看連續 M frames,如果 ho 都存在的話,才會保留。
action recognition:用 involve 的兩個 object 來判斷 action。
collaboration recognition:我們目前只考慮兩種情況
a. 當兩人同時在操作同一個物體時 b. 一人的物體在對另一人的物體做事
上層:
Visual sentence:
Grammar tree:
我主要負責的部分
Because hands are the main driving force in manipulation actions, so we need to have a robust hand detector.
Hand detection:
如果沒有 OpenPose 的 body or OpenPose 的 hand confidence 太低,就用 SSD。
Hand pair with objects:
Partially help object detection:
Data annotation - Setup VATIC server /教多個 undergrad 怎麼做 labeling
Result
我們在各種不同的測試範例中都可以跑出正確的 grammar tree:
FAQ
Challenges a. 手有時大/有時小 b. 不是每個 frame 都可以偵測到手
Mistakes/Failures a. IROS 投稿失敗
Enjoyed a.
Leadership
Conflicts
What you'd do differently
知識補充
OpenPose hand detector
YOLO
概念介紹: https://www.youtube.com/watch?v=4eIBisqx9_g
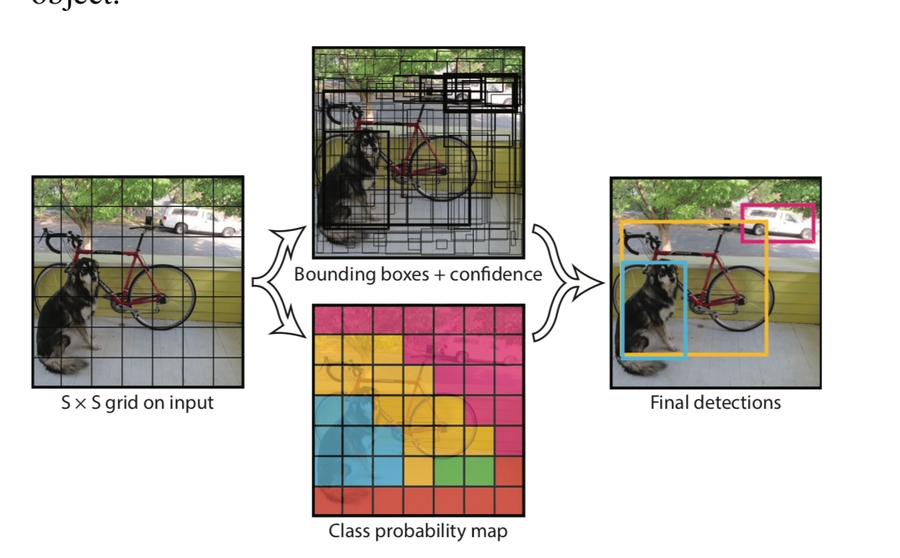
直接把圖片切成 SxS 個 grid,每個 grid 會有 B 個 bounding box
每個 bbox 都有 x, y, w, h, confidence(表示這個 box 裡有包含物體的機率
每個 grid 有 class probability
合併高 confidence 跟同個 class 的 box
概念圖如下:
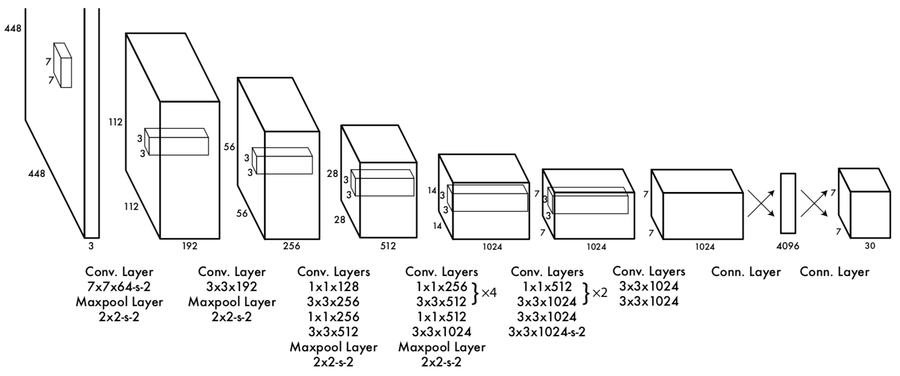
Network 架構圖如下:(最後的 7730 表示有 77 個 grid,每個 grid 有20個 class 的機率,跟兩個 bbox、每個 box 有 5 個值,所以總共有 20+25 = 30 個值)
Last updated